Supporting a New VDIF EDV¶
Users may encounter VDIF files with unusual headers not currently supported by Baseband. These may either have novel EDV, or they may purport to be a supported EDV but not conform to its formal specification. To handle such situations, Baseband supports implementation of new EDVs and overriding of existing EDVs without the need to modify Baseband’s source code.
The tutorials below assumes the following modules have been imported:
>>> import numpy as np
>>> import astropy.units as u
>>> from baseband import vdif, base as vlbi
VDIF Headers¶
Each VDIF frame begins with a 32-byte, or eight 32-bit word, header that is structured as follows:
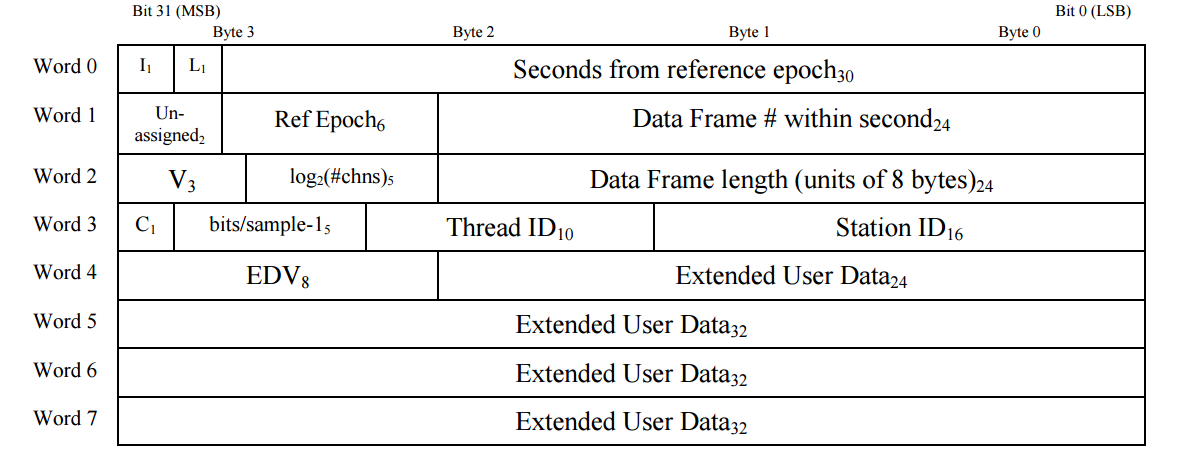
Schematic of the standard 32-bit VDIF header, from VDIF specification release 1.1.1 document, Fig. 3. 32-bit words are labelled on the left, while byte and bit numbers above indicate relative addresses within each word. Subscripts indicate field length in bits.¶
where the abbreviated labels are
\(\mathrm{I}_1\) - invalid data
\(\mathrm{L}_1\) - if 1, header is VDIF legacy
\(\mathrm{V}_3\) - VDIF version number
\(\mathrm{log}_2\mathrm{(\#chns)}_5\) - \(\mathrm{log}_2\) of the number of sub-bands in the frame
\(\mathrm{C}_1\) - if 1, complex data
\(\mathrm{EDV}_8\) - “extended data version” number; see below
Detailed definitions of terms are found on pages 5 to 7 of the VDIF specification document.
Words 4 - 7 hold optional extended user data, using a layout specified by the EDV, in word 4 of the header. EDV formats can be registered on the VDIF website; Baseband aims to support all registered formats (but does not currently support EDV = 4).
Implementing a New EDV¶
In this tutorial, we follow the implementation of an EDV=4 header. This would be a first and required step to support that format, but does not suffice, as it also needs a new frame class that allows the purpose of the EDV class, which is to independently store the validity of sub-band channels within a single data frame, rather than using the single invalid-data bit. From the EDV=4 specification, we see that we need to add the following to the standard VDIF header:
Validity header mask (word 4, bits 16 - 24): integer value between 1 and 64 inclusive indicating the number of validity bits. (This is different than \(\mathrm{log}_2\mathrm{(\#chns)}_5\), since some channels can be unused.)
Synchronization pattern (word 5): constant byte sequence
0xACABFEED, for finding the locations of headers in a data stream.Validity mask (words 6 - 7): 64-bit binary mask indicating the validity of sub-bands. Any fraction of 64 sub-bands can be stored in this format, with any unused bands labelled as invalid (
0) in the mask. If the number of bands exceeds 64, each bit indicates the validity of a group of sub-bands; see specification for details.
See Sec. 3.1 of the specification for best practices on using the invalid data bit \(\mathrm{I}_1\) in word 0.
In Baseband, a header is parsed using VDIFHeader,
which returns a header instance of one of its subclasses, corresponding to the
header EDV. This can be seen in the baseband.vdif.header module class
inheritance diagram. To support a new EDV, we create a new subclass to
baseband.vdif.VDIFHeader:
>>> class VDIFHeader4(vdif.header.VDIFHeader):
... _edv = 4
...
... _header_parser = vlbi.header.HeaderParser(
... (('invalid_data', (0, 31, 1, False)),
... ('legacy_mode', (0, 30, 1, False)),
... ('seconds', (0, 0, 30)),
... ('_1_30_2', (1, 30, 2, 0x0)),
... ('ref_epoch', (1, 24, 6)),
... ('frame_nr', (1, 0, 24, 0x0)),
... ('vdif_version', (2, 29, 3, 0x1)),
... ('lg2_nchan', (2, 24, 5)),
... ('frame_length', (2, 0, 24)),
... ('complex_data', (3, 31, 1)),
... ('bits_per_sample', (3, 26, 5)),
... ('thread_id', (3, 16, 10, 0x0)),
... ('station_id', (3, 0, 16)),
... ('edv', (4, 24, 8)),
... ('validity_mask_length', (4, 16, 8, 0)),
... ('sync_pattern', (5, 0, 32, 0xACABFEED)),
... ('validity_mask', (6, 0, 64, 0))))
VDIFHeader has a metaclass that ensures that
whenever it is subclassed, the subclass definition is inserted into the
VDIF_HEADER_CLASSES dictionary using
its EDV value as the dictionary key. Methods in
VDIFHeader use this dictionary to determine
the type of object to return for a particular EDV. How all this works is
further discussed in the documentation of the VDIF
baseband.vdif.header module.
The class must have a private _edv attribute for it to properly be
registered in VDIF_HEADER_CLASSES. It must
also feature a _header_parser that reads these words to return header
properties. For this, we use
baseband.base.header.HeaderParser. To initialize a header parser,
we pass it a tuple of header properties, where each entry follows the
syntax:
('property_name', (word_index, bit_index, bit_length, default))
where
property_name: name of the header property; this will be the key;word_index: index into the header words for this key;bit_index: index to the starting bit of the part used;bit_length: number of bits used, normally between 1 and 32, but can be 64 for adding two words together; anddefault: (optional) default value to use in initialization.
For further details, see the documentation of
HeaderParser.
Once defined, we can use our new header like any other:
>>> myheader = vdif.header.VDIFHeader.fromvalues(
... edv=4, seconds=14363767, nchan=1, samples_per_frame=1024,
... station=65532, bps=2, complex_data=False,
... thread_id=3, validity_mask_length=60,
... validity_mask=(1 << 59) + 1)
>>> myheader
<VDIFHeader4 invalid_data: False,
legacy_mode: False,
seconds: 14363767,
_1_30_2: 0,
ref_epoch: 0,
frame_nr: 0,
vdif_version: 1,
lg2_nchan: 0,
frame_length: 36,
complex_data: False,
bits_per_sample: 1,
thread_id: 3,
station_id: 65532,
edv: 4,
validity_mask_length: 60,
sync_pattern: 0xacabfeed,
validity_mask: 576460752303423489>
>>> myheader['validity_mask'] == 2**59 + 1
True
There is an easier means of instantiating the header parser. As can be seen in the
class inheritance diagram for the header module, many VDIF
headers are subclassed from other VDIFHeader
subclasses, namely VDIFBaseHeader and
VDIFSampleRateHeader. This is because many
EDV specifications share common header values, and so their functions and
derived properties should be shared as well. Moreover, header parsers can be
appended to one another [*], which saves repetitious coding because the first four
words of any VDIF header are the same. Indeed, we can create the same header
as above by subclassing VDIFBaseHeader:
>>> class VDIFHeader4Enhanced(vdif.header.VDIFBaseHeader):
... _edv = 42
...
... _header_parser = (vdif.header.VDIFBaseHeader._header_parser
... | vlbi.header.HeaderParser((
... ('validity_mask_length', (4, 16, 8, 0)),
... ('sync_pattern', (5, 0, 32, 0xACABFEED)),
... ('validity_mask', (6, 0, 64, 0)))))
...
... _properties = vdif.header.VDIFBaseHeader._properties + ('validity',)
...
... def verify(self):
... """Basic checks of header integrity."""
... super(VDIFHeader4Enhanced, self).verify()
... assert 1 <= self['validity_mask_length'] <= 64
...
... @property
... def validity(self):
... """Validity mask array with proper length.
...
... If set, writes both ``validity_mask`` and ``validity_mask_length``.
... """
... bitmask = np.unpackbits(self['validity_mask'].astype('>u8')
... .view('u1'))[::-1].astype(bool)
... return bitmask[:self['validity_mask_length']]
...
... @validity.setter
... def validity(self, validity):
... bitmask = np.zeros(64, dtype=bool)
... bitmask[:len(validity)] = validity
... self['validity_mask_length'] = len(validity)
... self['validity_mask'] = np.packbits(bitmask[::-1]).view('>u8')
Here, we set edv = 42 because VDIFHeader’s
metaclass is designed to prevent accidental overwriting of existing
entries in VDIF_HEADER_CLASSES. If we had used
_edv = 4, we would have gotten an exception:
ValueError: EDV 4 already registered in VDIF_HEADER_CLASSES
We shall see how to override header classes in the next section. Except for
the EDV, VDIFHeader4Enhanced’s header structure is identical
to VDIFHeader4. It also contains a few extra functions to enhance the
header’s usability.
The verify function is an optional function that runs upon header
initialization to check its veracity. Ours simply checks that the
validity mask length is in the allowed range, but we also call the same function
in the superclass (VDIFBaseHeader), which
checks that the header is not in 4-word “legacy mode”, that the header’s
EDV matches that read from the words, that there are eight words, and
that the sync pattern matches 0xACABFEED.
The validity_mask is a bit mask, which is not necessarily the easiest to
use directly. Hence, implement a derived validity property that generates
a boolean mask of the right length (note that this is not right for cases
whether the number of channels in the header exceeds 64). We also define a
corresponding setter, and add this to the private _properties attribute,
so that we can use validity as a keyword in fromvalues:
>>> myenhancedheader = vdif.header.VDIFHeader.fromvalues(
... edv=42, seconds=14363767, nchan=1, samples_per_frame=1024,
... station=65532, bps=2, complex_data=False,
... thread_id=3, validity=[True]+[False]*58+[True])
>>> myenhancedheader
<VDIFHeader4Enhanced invalid_data: False,
legacy_mode: False,
seconds: 14363767,
_1_30_2: 0,
ref_epoch: 0,
frame_nr: 0,
vdif_version: 1,
lg2_nchan: 0,
frame_length: 36,
complex_data: False,
bits_per_sample: 1,
thread_id: 3,
station_id: 65532,
edv: 42,
validity_mask_length: 60,
sync_pattern: 0xacabfeed,
validity_mask: [576460752303423489]>
>>> assert myenhancedheader['validity_mask'] == 2**59 + 1
>>> assert (myenhancedheader.validity == [True]+[False]*58+[True]).all()
>>> myenhancedheader.validity = [True]*8
>>> myenhancedheader['validity_mask']
array([255], dtype=uint64)
Note
If you have implemented support for a new EDV that is widely used, we encourage you to make a pull request to Baseband’s GitHub repository, as well as to register it (if it is not already registered) with the VDIF consortium!
Replacing an Existing EDV¶
Above, we mentioned that VDIFHeader’s
metaclass is designed to prevent accidental overwriting of existing
entries in VDIF_HEADER_CLASSES, so attempting
to assign two header classes to the same EDV results in an exception. There
are situations such the one above, however, where we’d like to replace
one header with another.
To get VDIFHeader to use VDIFHeader4Enhanced
when edv=4, we can manually insert it in the dictionary (keeping a
copy of the original dict so we can updo later):
>>> original_header_classes = vdif.header.VDIF_HEADER_CLASSES.copy()
>>> vdif.header.VDIF_HEADER_CLASSES[4] = VDIFHeader4Enhanced
Of course, we should then be sure that its _edv attribute is correct:
>>> VDIFHeader4Enhanced._edv = 4
VDIFHeader will now return instances of
VDIFHeader4Enhanced when reading headers with edv = 4:
>>> myheader = vdif.header.VDIFHeader.fromvalues(
... edv=4, seconds=14363767, nchan=1,
... station=65532, bps=2, complex_data=False,
... thread_id=3, validity=[True]*60)
>>> assert isinstance(myheader, VDIFHeader4Enhanced)
Note
Failing to modify _edv in the class definition will lead to an
EDV mismatch when verify is called during header initialization.
This can also be used to override VDIFHeader’s
behavior even for EDVs that are supported by Baseband, which may
prove useful when reading data with corrupted or mislabelled headers. To
illustrate this, we attempt to read in a corrupted VDIF file originally
from the Dominion Radio Astrophysical Observatory. This file can be
imported from the baseband data directory:
>>> from baseband.data import SAMPLE_DRAO_CORRUPT
Naively opening the file with
>>> fh = vdif.open(SAMPLE_DRAO_CORRUPT, 'rs')
will lead to an AssertionError. This is because while the headers of the
file use EDV=0, it deviates from that EDV standard by storing additional
information an: an “eud2” parameter in word 5, which is related to the sample time.
Furthermore, the bits_per_sample setting is incorrect (it should be 3 rather
than 4 – the number is defined such that a one-bit sample has a
bits_per_sample code of 0). Finally, though not an error, the
thread_id in word 3 defines two parts, link and slot, which
reflect the data acquisition computer node that wrote the data to disk.
To accommodate these changes, we design an alternate header. We first
pop the EDV = 0 entry from VDIF_HEADER_CLASSES:
>>> vdif.header.VDIF_HEADER_CLASSES.pop(0)
<class 'baseband.vdif.header.VDIFHeader0'>
We then define a replacement class:
>>> class DRAOVDIFHeader(vdif.header.VDIFHeader0):
... """DRAO VDIF Header
...
... An extension of EDV=0 which uses the thread_id to store link
... and slot numbers, and adds a user keyword (illegal in EDV0,
... but whatever) that identifies data taken at the same time.
...
... The header also corrects 'bits_per_sample' to be properly bps-1.
... """
...
... _header_parser = (vdif.header.VDIFHeader0._header_parser
... | vlbi.header.HeaderParser((
... ('link', (3, 16, 4)),
... ('slot', (3, 20, 6)),
... ('eud2', (5, 0, 32)))))
...
... def verify(self):
... pass # this is a hack, don't bother with verification...
...
... @classmethod
... def fromfile(cls, fh, edv=0, verify=False):
... self = super(DRAOVDIFHeader, cls).fromfile(fh, edv=0,
... verify=False)
... # Correct wrong bps
... self.mutable = True
... self['bits_per_sample'] = 3
... return self
We override verify because VDIFHeader0’s
verify function checks that word 5 contains no data. We also override
the fromfile class method such that the bits_per_sample property
is reset to its proper value whenever a header is read from file.
We can now read in the corrupt file by manually reading in the header, then the payload, of each frame:
>>> fh = vdif.open(SAMPLE_DRAO_CORRUPT, 'rb')
>>> header0 = DRAOVDIFHeader.fromfile(fh)
>>> header0['eud2'] == 667235140
True
>>> header0['link'] == 2
True
>>> payload0 = vdif.payload.VDIFPayload.fromfile(fh, header0)
>>> payload0.shape == (header0.samples_per_frame, header0.nchan)
True
>>> fh.close()
Reading a frame using VDIFFrame will still fail,
since its _header_class is VDIFHeader,
and so VDIFHeader.fromfile,
rather than the function we defined, is used to read in headers. If we
wanted to use VDIFFrame, we would need to set
VDIFFrame._header_class = DRAOVDIFHeader
before using baseband.vdif.open(), so that header files are read
using DRAOVDIFHeader.fromfile.
A more elegant solution that is compatible with baseband.vdif.base.VDIFStreamReader
without hacking baseband.vdif.frame.VDIFFrame involves modifying the
bits-per-sample code within __init__(). Let’s remove our previous custom
class, and define a replacement:
>>> vdif.header.VDIF_HEADER_CLASSES.pop(0)
<class '__main__.DRAOVDIFHeader'>
>>> class DRAOVDIFHeaderEnhanced(vdif.header.VDIFHeader0):
... """DRAO VDIF Header
...
... An extension of EDV=0 which uses the thread_id to store link and slot
... numbers, and adds a user keyword (illegal in EDV0, but whatever) that
... identifies data taken at the same time.
...
... The header also corrects 'bits_per_sample' to be properly bps-1.
... """
... _header_parser = (vdif.header.VDIFHeader0._header_parser
... | vlbi.header.HeaderParser((
... ('link', (3, 16, 4)),
... ('slot', (3, 20, 6)),
... ('eud2', (5, 0, 32)))))
...
... def __init__(self, words, edv=None, verify=True, **kwargs):
... super(DRAOVDIFHeaderEnhanced, self).__init__(
... words, verify=False, **kwargs)
... self.mutable = True
... self['bits_per_sample'] = 3
...
... def verify(self):
... pass
If we had the whole corrupt file, this might be enough to use the stream reader without further modification. It turns out, though, that the frame numbers are not monotonic and that the station ID changes between frames as well, so one would be better off making a new copy. Here, we can at least now read frames:
>>> fh2 = vdif.open(SAMPLE_DRAO_CORRUPT, 'rb')
>>> frame0 = fh2.read_frame()
>>> assert np.all(frame0.data == payload0.data)
>>> fh2.close()
>>> vdif.header.VDIF_HEADER_CLASSES = original_header_classes
Reading frames using VDIFFileReader.read_frame will now work as well, but
reading frame sets using VDIFFileReader.read_frameset will still fail.
This is because the frame and thread numbers that function relies on
are meaningless for these headers, and grouping threads together using
the link, slot and eud2 values should be manually performed
by the user.